Cet article décrit les principes et pratiques associés au Continous Delivery qui permettent d'appliquer concrètement le premier principe Agile : "Notre plus haute priorité est de satisfaire le client en livrant rapidement et régulièrement des fonctionnalités à grande valeur ajoutée". Pour éviter toute confusion, précisons qu'il ne traite pas du processus de réalisation (Scrum ou Kanban par exemple) mais du processus de "déploiement" convertissant le code source produit par une ou plusieurs équipes de développement en une application utilisable en production. L'essentiel des notions abordées sont issues du livre Continuous Delivery de Jez Humble et David Farley.
Enjeux
L'objectif premier est la satisfaction du client. Cette satisfaction s'obtient en offrant bien sûr un logiciel qui répond aux attentes des utilisateurs en termes de fonctionnalités, ergonomie, performance et robustesse. Mais elle s'obtient également en réduisant autant que possible le délais entre l'idée (ou la demande) et la mise à disposition de la nouvelle fonctionnalité (ou évolution ou correctif) associée.
En complément des processus de réalisation Agile (Scrum ou Kanban par exemple), les principes et pratiques abordés dans cet article rendent possible l'adoption d'un rythme de livraison aux utilisateurs en production fréquent et rapide. Un rythme hebdomadaire par exemple avec une durée de livraison de quelques seconde à moins de 2 heures y compris dans des contextes complexes. Comme le vivent déjà certaines entreprises.
Principes du Continuous Delivery
Tout repose sur 2 principes fondamentaux :
- Automatiser la livraison avec pour objectif la mise au point d'une procédure "pousse bouton" permettant de rendre le processus de déploiement fiable et répétable (sans risque d'erreur humaine).
- Livrer fréquemment afin d'éprouver, fiabiliser la procédure, mais surtout nous donner un feedback au plus tôt afin de réduire autant que possible les coûts d'ajustement et par la même occasion la frustration (aussi bien celle des développeurs obligés de retravailler leur code alors qu'ils sont déjà passés à autre chose et les utilisateurs obligés de patienter trop longtemps).
Le pipeline de déploiement

{kind=link}
Le circuit que parcourent les changements apportés au code à partir du commit du développeur jusqu'à sa livraison en production est appelé le "pipeline de déploiement".
Le schéma ci contre illustre les principales étapes d'un pipeline de base (dont certaines sont parallélisables). On peut voir ce dernier comme une extension de l'Intégration Continue.
Pour l'anecdote, le choix du terme "Pipeline" n'est pas inspiré des canalisations de type oléoduc mais du fonctionnement des microprocesseurs.
Pratiques
Les pratiques suivantes permettent d'appliquer concrètement les principes évoqués plus haut.
Builder ses binaires une seule fois
Des changements ou erreurs humaines peuvent s'inviter entre différents build portant sur une même version du code source. Un changement de paramètre de compilation ou une erreur de tag par exemple. Changements qui peuvent rendre l'investigation difficile en cas de problème. C'est pourquoi, une fois que les binaires générés sont réputés fonctionner sur le premier environnement, ce sont eux qu'on utilisera sur les suivants. Par la même occasion, le délais de build est autant de temps de gagné pour les autres étapes du pipeline (ce qui est fait n'est plus à faire).
Même procédure pour chaque environnement
Afin d'utiliser et donc tester des centaines de fois la procédure de déploiement et ainsi la fiabiliser, nous avons intérêt à faire en sorte que ce soit la même pour l'ensemble des environnements. Ce qui va nous obliger - pour notre plus grand bien - à externaliser toutes les variables d'environnement. Ces dernières trouveront généralement leur place dans un fichier de configuration type "properties" qui lui même trouvera sa place dans le gestionnaire de version (ce qui permettra de faciliter les investigations en cas de problème).
Tests de fumée sur les déploiements
Livrer en production ou autre environnement à enjeu n'est pas suffisant. Nous devons aussi vérifier que le tout fonctionne. Les tests de fumée remplissent ce rôle. Connexion à la page d'accueil de l'application web, vérification de la disponibilité de la base de données, ping du web-service d'une application tierce, etc.
Déployer sur une copie de la production
L'un des pièges courant concernant les problèmes de mise en production est celui issu des différences entre les environnements du projet. Différence de compilateur, de version d'OS (voire pire d'OS tout court), de stack, de patchs de l'OS, de système de répartition de charge, de configuration réseau (ex : emplacement par rapport au proxy), etc.
Nous avons tout intérêt à uniformiser tous les environnements et suivre avec rigueur le moindre changement apporté. Le recours à des serveurs virtuels peut faciliter les choses et accélérer au passage le délais de mise en disposition des environnements.
Chaque changement se propage sur tout le pipeline

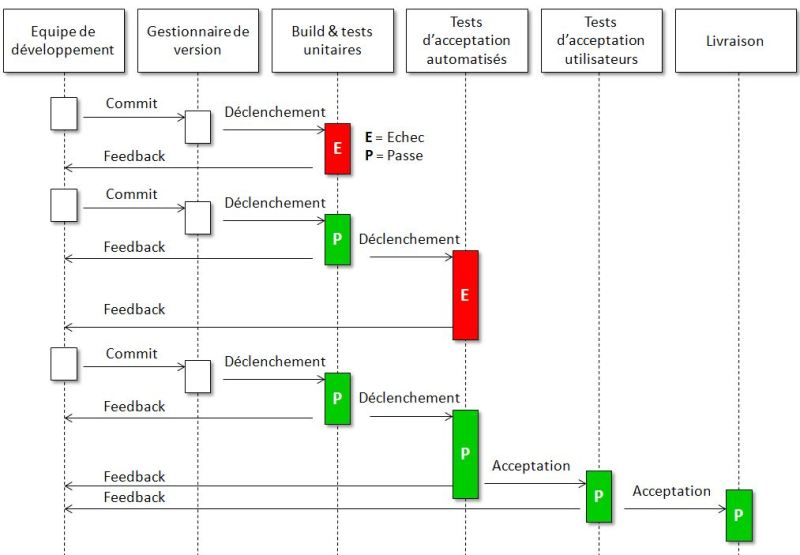{kind=link}
Chaque commit est candidat à traverser les étapes du pipeline. Le diagramme ci contre décrit le mouvement d'un changement de code à travers le pipeline de déploiement.
Il ne décrit cependant pas le cas de figure assez fréquent selon lequel de nombreux commits successifs sont réalisés avant que l'Intégration Continue ai eu le temps de vérifier le premier. Dans ce cas, une fois qu'elle a terminé, elle prendra la dernière version du code et recommencera. Ce qui peut rendre l'analyse difficile en cas d'échec de l'intégration continue (lequel des commits est coupable ?). Dans ce cas, on pourra demander manuellement à l'outil d'Intégration Continue de tester chaque commit un à un jusqu'à rencontrer l'échec et donc identifier le commit fautif.
En cas d'échec sur une section du pipeline, on s'arrête
Nous l'avons vu, l'un des principes fondamentaux est d'obtenir un feedback au plus tôt afin de limiter les coûts et le stress associés à un défaut. Coût et stress qui ne font que grossir avec le temps. Dès qu'un voyant s'allume, nous avons donc tout intérêt à réagir au plus vite. Il ne s'agit pas forcément de mobiliser toute l'équipe mais à minima une personne doit arrêter ce qu'elle est en train de faire pour retirer le "grain de sable" de l'engrenage. Nous devons par exemple être vigilant le soir lors du dernier commit de la journée en vérifiant que ce dernier a bien passé toute la chaîne automatisée du pipeline avant de partir.
Etape de commit
La première étape du pipeline, celle du commit, est peut être celle qui comporte le plus d'enjeux. L'objectif de cette étape est d'éliminer les build impropres à une livraison en production et de nous avertir au plus tôt en cas de build cassé.
C'est pour cette raison qu'elle couvre généralement les vérifications suivantes :
- Compilation du code
- Tests de commit (sous ensemble de tests unitaires automatisés réputés rapides à exécuter et permettant de détecter un maximum de régressions. Ce sous ensemble s'affine au fil de l'eau.)
- Création des binaires (qui seront utilisés plus tard)
- Analyse du code (taux de couverture de test, taux de code dupliqué, complexité cyclomatique, nombre de warnings, formatage du code, etc)
- Préparation des artéfacts (bases de données de test par exemple)
Toutes ces vérifications sont généralement automatisables par les outils d'Intégration Continue.
A chaque modification du code, une nouvelle instance du pipeline est créée. Le paragraphe Outils comporte la capture d'écran d'un outil de Continuous Delivery qui illustre bien ce principe (chaque ligne correspond à une instance du pipeline et donc à un build distinct).
Etape de tests d'acceptation
Cette étape a également une grande importance. Plutôt que de vérifier très localement le bon fonctionnement du code (rôles des tests unitaires automatisés), elle contrôle la bonne couverture du besoin et la non régression fonctionnelle. Elle repose généralement sur des "spécifications par l'exemple" et outils associés (Cucumber, Fitnesse ou Concordium par exemple). Ces tests sont sous la responsabilité collective du métier, des analystes, testeurs et développeurs.
Recourir aux branches avec modération
L'idéal est d'avoir un code constamment livrable malgré les changements constants apportées par l'équipe de développement. Le recours aux branches est tentant. Cependant, il implique une charge de travail importante et des risques élevés même avec les meilleurs outils du monde. L'effort de fusion (merge) et la gestion des conflits (sans avoir forcément les développeurs concernés sous la main) ainsi que la déconnexion à l'Intégration Continue sont de bons exemples de charge de travail et de risques occasionnés par les branches. Plus la durée de vie des branches est longue plus ces contraintes grossissent.
Voici quelques pratiques permettant d'éviter autant que possible le recours aux branches :
- Nouvelle fonctionnalité : Que faire pour réaliser une nouvelle fonctionnalité ou un nouvel ensemble de fonctionnalités dont le développement peut durer plus d'une semaine alors que notre rythme de livraison en production est hebdomadère ? En commitant sur le trunk les modifications de code (sans branche donc) tout en rendant la nouvelle fonctionnalité invisible pour l'utilisateur tant qu'elle n'est pas terminée (avec une URI dédiée par exemple dans le cas d'un site web).
- Gros Refactoring : En cas de gros refactoring, découper dans la mesure du possible le travail en petits incréments et faire le refactoring pas à pas sur le trunk en s'appuyant sur la ceintures de tests automatisés. Le découpage demande un peu de créativité mais c'est plus sûr. Cela permet également de pouvoir s'arrêter en cours de route au besoin. Ce qui est très risqué/stressant en cas d'utilisation d'une branche car on vit alors avec la peur d'avoir un trunk qui évolue trop vite et qui rendra le merge douloureux et risqué.
- Refactoring à grande échelle : Mettre en place une couche d'abstraction au dessus de la zone à refactorer puis réaliser une nouvelle implémentation sous cette couche à côté de l'implémentation existante.
Il est recommandé d'utiliser les branches uniquement dans le cas où ces dernières n'auront pas à être fusionnées. Les branches de release ou de spike (dont le code est jetable) par exemple. Lorsque la fréquence des livraisons en production est élevée (par exemple de l'ordre de la semaine), les branches de release deviennent inutiles. C'est souvent moins coûteux et plus simple d'attendre la prochaine version plutôt qu'avoir recours à un patch et sa branche.
Petit bémol tout de même : Les gestionnaires de version distribués comme GIT changent la donne car ils occasionnent un changement de paradigme. Ce dernier réconcilie peut être le recours aux branches et le Continuous Delivery.
Outils

Outil permettant de suivre et gérer les différentes instances du pipeline de déploiement.
{kind=link}
Le Continuous Delivery est une démarche très transverses qui touche - directement ou indirectement - à la fois le processus de réalisation, la gestion des tests, les pratiques de développement et la gestion des environnements. Il n'est donc pas surprenant de trouver une grande quantité d'outils en tout genre gratuits ou payants pour atteindre les objectifs visés.
Voici un bref article qui répertorie de tels outils.
Bénéfices du Continuous Delivery
- Feedback rapide : Plus un défaut est corrigé tard, plus il coûte cher (investiguer, reproduire le défaut, revenir sur du code qui n'est pas forcément le sien, qualifier/estimer/arbitrer/planifier/livrer/tester la correction, etc). Le pipeline de Continuous Delivery offre un feedback rapide et évite ainsi des gaspillages parfois considérables. Un feedback quasi immédiat au niveau de l'Intégration Continue et à la semaine au niveau de l'utilisateur final.
- Meilleure qualité : Il n'est pas surprenant d'apprendre que les équipes ayant mis en place l'intégralité d'un pipeline de Continuous Delivery en plus de piloter les développements par les tests parviennent aux termes de 6 mois de développement avec une quantité d'anomalies se comptant sur les doigts d'une main. A tel point qu'un outil de suivi d'anomalie ou même un indicateur de volume d'anomalies deviennent tout bonnement inutiles. Le Graal de toute équipe de développement en somme.
- Moins de stress : Le stress porte principalement sur 2 aspects. Les jalons à tenir qui maintiennent un niveau de stress dans la durée et croissant. Et la livraison qui repose sur une procédure généralement très manuelle et porteuse de nombreux changements (le fruits de plusieurs semaines ou mois de travail). En cas de livraison hebdomadaire avec des procédures automatisées, ces facteurs de stress sont considérablement réduits.
- Bouton "Retour en arrière" : L'automatisation complète de la livraison à partir d'un binaire déjà construit (identique pour chaque environnement) rend la procédure de livraison rapide quelque soit la version visée. En cas de problème avec la livraison de la dernière version, on pourra revenir en arrière facilement grâce à cette même procédure qui aura alors pour cible les binaires de la version précédente.
- Week-end pour soi : L'automatisation complète et la fiabilisation de la procédure de livraison rendent cette dernière rapide et presque anecdotique. Si rapide qu'il devient inutile de mobiliser une équipe entière tout un samedi pour assurer la livraison avant que les utilisateurs reprennent le travail.
- Meilleure relation client - fournisseur : Nous l'avons évoqué en introduction l'objectif premier est la satisfaction du client (et des utilisateurs). Une fois atteint, le principal bénéfice qui en découle est l'acquisition d'une relation de confiance voire de "réel plaisir à travailler ensemble" entre l'équipe de développement, le client et les utilisateurs.
- Possibilité d'audit de la livraison : Comment auditer une procédure de livraison manuelle qui s'est mal déroulée ? On ne peut pas se reposer sur la procédure papier car elle ne nous dit pas où une erreur humaine à pu se glisser. En revanche une procédure automatique est auditable.
Oui mais...
Beaucoup d'entre nous connaissent sans doute un contexte bien cloisonné au sein duquel l'équipe de développement jette son build ainsi que la procédure d'installation associée par dessus le mur qui la sépare des exploitants (ceux qui mettent l'application en production). Avec toutes le contraintes que ça implique. Que faire dans pareille situation ? Faut il attendre le changement culturel tant attendu qui cessera d'isoler les compétences ? Le risque est d'attendre longtemps - surtout dans une grosse entreprise - même si les courants DevOps prendront sans doute de plus en plus d'ampleur (après tout c'est du bon sens, une fois de plus).
Au lieu d'attendre, c'est sans doute à l'équipe de développement de faire le premier pas. En fournissant avec ses binaires une procédure de livraison ad hoc automatisée type "pousse bouton". En échange de cette promesse de "don" aux exploitants (heureux de ne pas avoir une centaine de gestes à exécuter avec le risque de se tromper), l'équipe de développement peut légitimement demander un environnement iso-prod (non pas en termes de puissance mais d'architecture technique avec les même version d'OS, même systèmes de répartition de charge, etc) à sa main. C'est cet environnement qui leur permettra de réaliser, utiliser et fiabiliser cette procédure "pousse bouton". Si le budget d'automatisation est limité, elle automatisera petit bout par petit bout, réduisant toujours un peu plus le délais de livraison et les risques d'erreur.
Pour aller plus loin
- Le site internet de référence sur le sujet.
- Le livre de référence sur le sujet.